This document outlines the functionality and benefits of qibb’s Job Management capabilities, enabled by Checkpoint Nodes strategically placed within your flows. This feature empowers you with enhanced job tracking, monitoring, and control, providing granular management over job processing for increased reliability and flexibility.
Understanding Checkpoint Nodes
qibb’s Checkpoint Nodes act as control points within your flow, allowing you to observe and manipulate jobs as they progress. They provide a robust framework for managing the lifecycle of your jobs, from initiation to completion or termination.
Key Capabilities
Here's a breakdown of the powerful controls offered by Checkpoint Nodes:
-
Job Checkpoints: Clearly mark significant stages in your job's journey, such as the start, intermediate progress points, and final completion for success and failure cases. This provides a visual and auditable trail of execution.
-
Job Scheduling & Timeouts: Plan the execution of individual jobs for a future time and define maximum execution durations. Jobs exceeding these timeouts can be automatically flagged as failed.
-
Retries & Cancellation: Implement automatic retry mechanisms for failed jobs, with configurable limits and backoff strategies. You also have the ability to manually retry or cancel jobs as needed.
-
Queue Management: Optimize job processing with features like priority queuing (processing higher-priority jobs first), rate limiting (controlling the rate of jobs leaving a checkpoint), and the ability to temporarily pause and resume checkpoint queues.
-
Approval-Based "Wait" Checkpoints: Introduce manual approval steps into your flow. Jobs reaching a "Wait" checkpoint will be held until explicitly released via user interface in the Portal, an injected message command in the flow or API call.
-
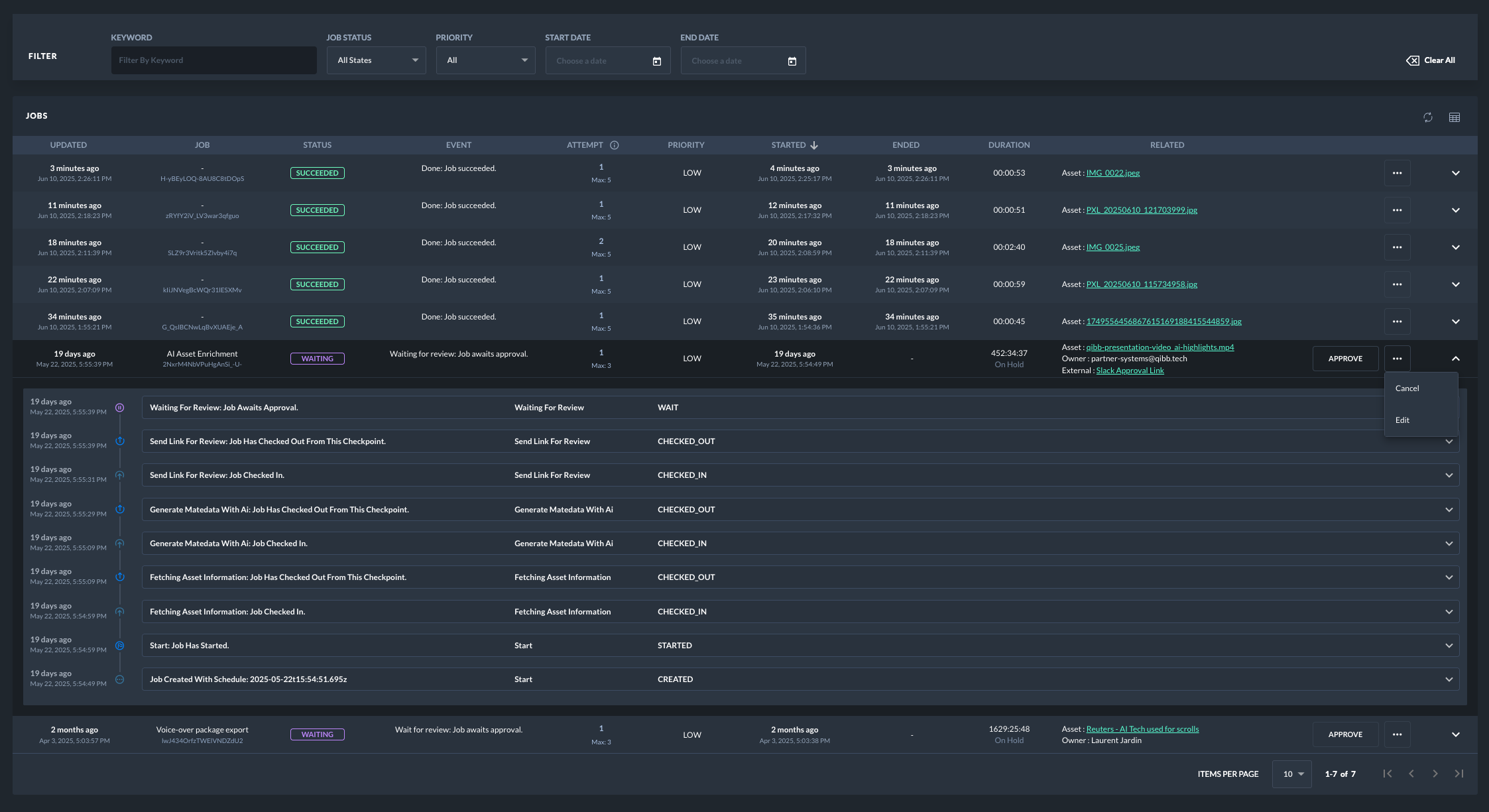
Browse & Search: Effortlessly track and analyze all jobs of an app through a dedicated interface in the qibb Portal, offering multiple filters and full-text search capabilities. This includes searching across job metadata and the complete job lifecycle. For audit purposes, you can inspect the event history and snapshotted message properties for each job.
Benefits of Using Checkpoint Nodes
Integrating Checkpoint Nodes into your flows offers several significant advantages:
-
Enhanced Job Tracking: Gain complete visibility into the status and progression of your jobs.
-
Improved Reliability: Implement automatic retries and timeouts to handle transient failures and prevent indefinite job hangs.
-
Increased Control: Manually intervene in job processing through cancellation, retries, and approval mechanisms.
-
Optimized Resource Utilization: Manage concurrent job execution with rate limiting and prioritize critical tasks with priority queuing.
-
Greater Flexibility: Schedule jobs for future execution and introduce manual approval steps for critical processes.
-
Resilience: Jobs persist through platform downtime or upgrades, ensuring continuity of processing. Stalled jobs are automatically flagged for attention.
-
Comprehensive Auditing: Maintain a detailed history of job progression at each checkpoint, including custom metadata.
Using Checkpoint Nodes in Your Flows
When designing your flows, you can strategically place different types of checkpoint nodes to implement the desired control mechanisms:
-
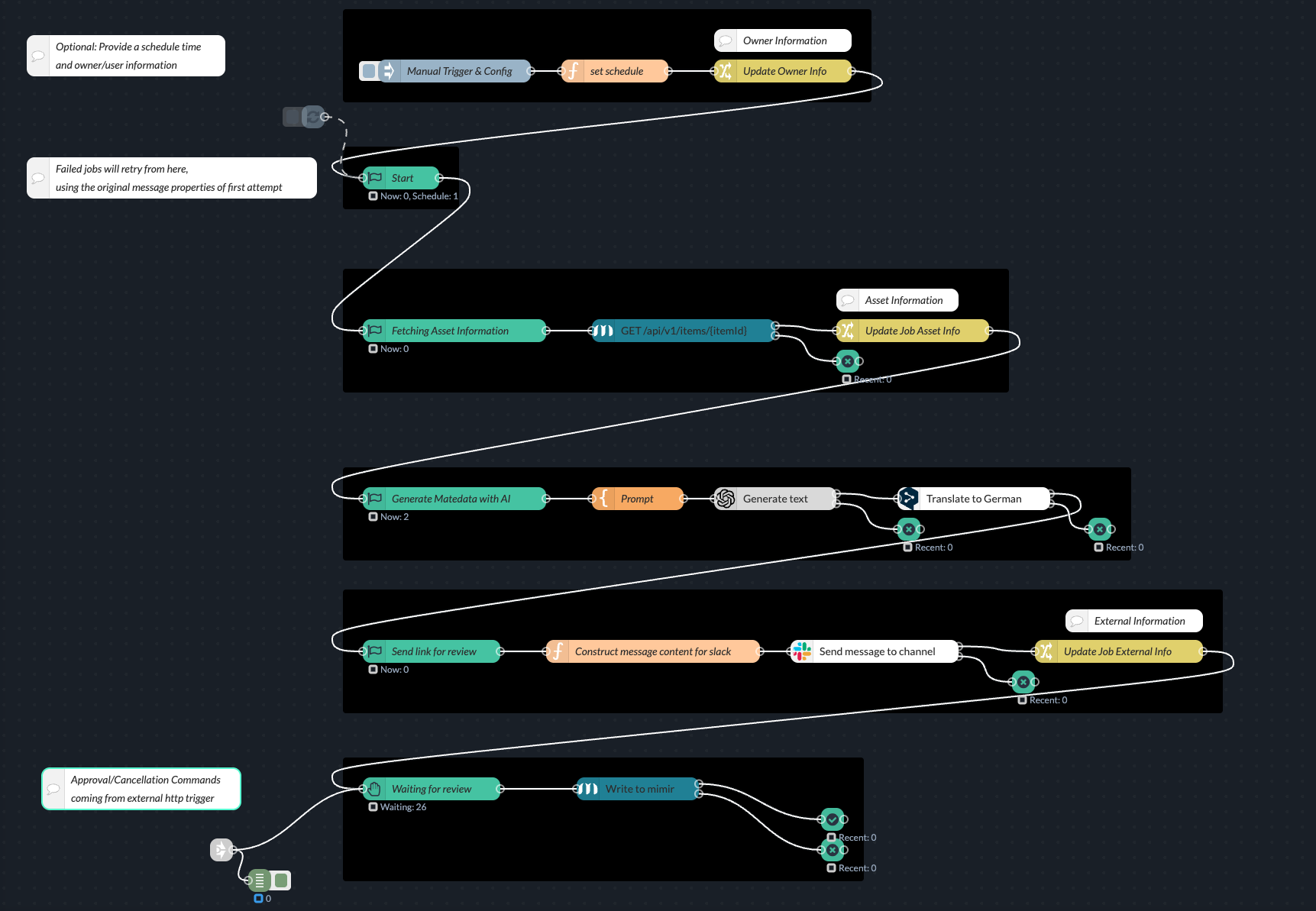
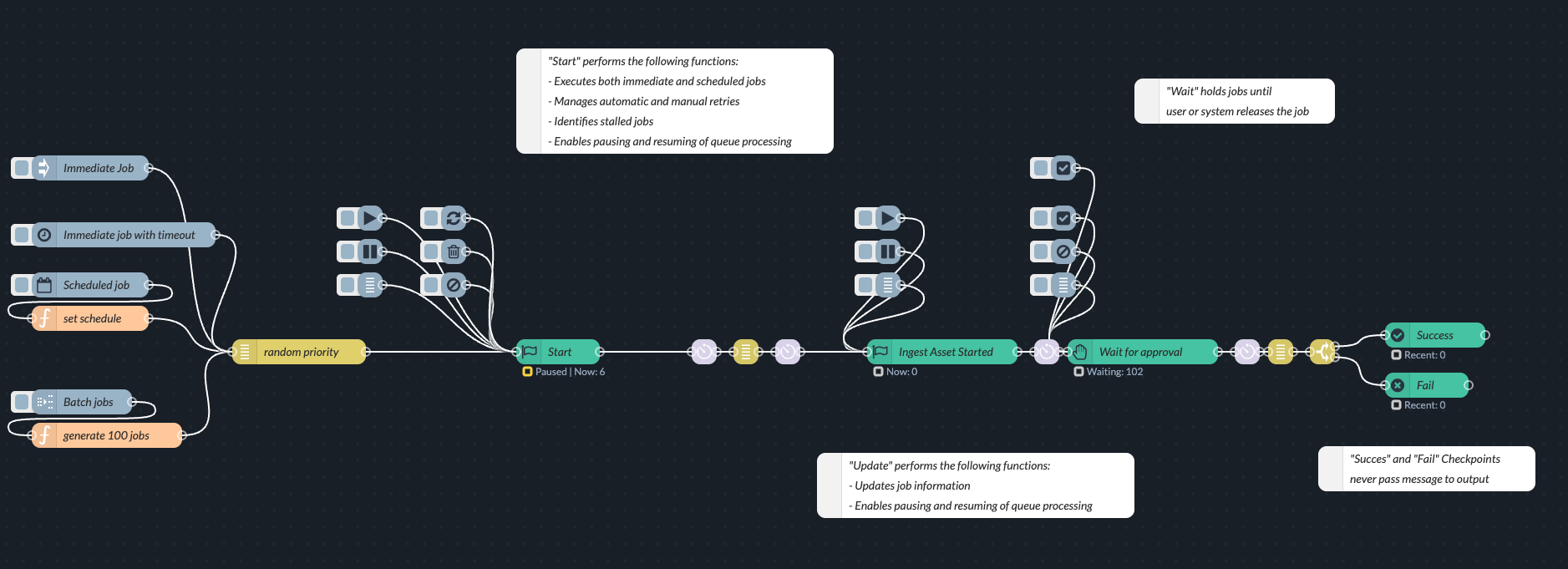
Start Checkpoint: Typically placed at the beginning of a job's flow. It can handle automatic retries for failed jobs.
-
Update Checkpoint: Used to mark progress or intermediate stages of a job. Supports pausing and resuming the queue.
-
Wait Checkpoint: Holds incoming jobs until they are manually or programmatically released.
-
Success Checkpoint: Indicates the successful completion of a job.
-
Fail Checkpoint: Indicates the failed completion of a job.
|
|
|
Managing Jobs in the Portal
The qibb Portal provides a dedicated interface for managing jobs processed through Checkpoint Nodes at the space level:
-
Job Overview: View a comprehensive list of jobs with their current status, description, and relevant metadata.
-
Filtering and Searching: Utilize multiple filters (e.g., status, checkpoint, creation time) and full-text search to quickly locate specific jobs.
-
Job Actions: Perform control actions on individual jobs, including:
-
Approve: Release jobs held at "Wait" checkpoints.
-
Retry: Manually trigger a retry attempt for a failed job.
-
Cancel: Terminate a pending or running job.
-
Delete: Remove a job from the system.
-
Edit: Modify certain job properties (if supported).
-
Implementation Details and Considerations
-
Resilience: Checkpoints ensure job persistence during downtime and app upgrades. Automatic retry rules aid in recovering from failures. The platform's architecture minimizes dependencies, allowing job and queue operation even during network disruptions. Cluster backups provide disaster recovery for job states and queues.
-
Pause & Resume Checkpoints: Start and Update Checkpoints can be paused and resumed via message commands, temporarily halting or restarting job processing at that point.
-
Approve Jobs: "Wait" Checkpoints hold jobs until a release command is issued through the UI or API.
-
Cancel Jobs: Jobs can be canceled individually using a specific message command referencing the job ID.
-
Delete Jobs: Individual jobs can be permanently removed using a message command with the job ID.
-
Schedule Jobs: Jobs can be scheduled for future execution by including an ISO date string in the
msg.scheduled_atproperty. -
Time Outs for Jobs: Define a timeout period in seconds using the
msg.timeout_in_secproperty. Jobs exceeding this duration from their creation time will be flagged as failed. -
Priority Queuing: Assign a priority level to jobs using the
msg.priorityproperty (higher number indicates higher priority). The queue will dynamically reorder to process higher-priority jobs first. -
Rate Limiting: Configure the maximum number of jobs concurrently leaving a checkpoint (options: 1, 10, 50, 100 jobs/second).
-
Automatic Retry for Jobs: The Start Checkpoint can be configured to automatically retry failed jobs. Configure the maximum number of attempts in the node properties. The original message at the time of job creation will be re-injected during retry.
-
Manual Retry for Jobs: Trigger a manual retry for a specific job ID via a message command. This bypasses the automatic retry limits, allowing for troubleshooting.
-
Job Tracking: The system automatically tracks job status (pending, running, success, fail) along with relevant metadata and a history of checkpoint transitions. Custom metadata structures for external IDs are also supported.
-
Flow Editor Interface: The flow editor provides visual indicators and interactive elements for Checkpoint Nodes:
-
See the current queue count for each checkpoint in the node status label.
-
View the job queue of a checkpoint in the debug sidebar.
-
Perform actions like deleting, canceling, releasing, pausing, resuming, manually retrying, and scheduling jobs using inject nodes with specific commands.
-
Configure rate limits per checkpoint.
-
Configure automatic retry attempts for the Start Checkpoint (For other checkpoint types, the setting will be ignored.)
-
-
Automatic Cleanup of Jobs: Future updates will introduce automatic deletion of old jobs based on configurable data retention policies to manage storage and prevent overflow.
Flows triggered by HTTP requests (via HTTP-in node) are supported by checkpoints under the following restrictions:
To leverage all checkpoint features, immediately handle incoming HTTP requests and remove the msg.res object before the message reaches the first checkpoint. Otherwise certain features will be automatically disabled, including queuing, rate limiting, wait/approve, and retries for that specific job, and a warning will be displayed in the debug sidebar. Jobs with the msg.res object will bypass queues and paused checkpoints.
Custom Metadata and Job Events
Checkpoint Nodes provide powerful capabilities for auditing and tracking your jobs, primarily through the use of custom metadata and automatically generated job events.
Custom Metadata for Enhanced Tracking
You can enrich your job records with custom metadata by adding properties to the msg object (e.g., msg.payload.customer_id, msg.asset.file_type). This allows you to store specific business-relevant information alongside your job.
Beyond arbitrary custom fields, qibb also supports a set of standardized metadata fields within msg.qibb for common tracking needs:
-
owner_id,owner_name,owner_url -
asset_id,asset_name,asset_url -
external_id,external_name,external_url
These standardized fields are specifically displayed in a dedicated column of the Jobs Table within the qibb Portal and are searchable, making it easier to filter and find jobs related to particular external systems, assets, or owners. Custom metadata (both standardized and user-defined) enhances job searchability, provides crucial context in the Portal, and forms a key part of your job's auditable trail.
Comprehensive Job Event History
As jobs progress through Checkpoint Nodes, the system automatically generates job events. Each event records a significant transition or action in the job's lifecycle, such as:
-
CREATED: When a job is initiated at a Start Checkpoint.
-
STARTED: When a job begins leaves a Start Checkpoint.
-
CHECKED_OUT: When a job leaves an Update checkpoint.
-
WAIT: When a job enters a Wait Checkpoint.
-
APPROVED: When a job is released from a Wait Checkpoint.
-
SCHEDULED_FOR_RETRY: When a job is scheduled for a retry attempt.
-
SUCCEEDED: When a job reaches a Success Checkpoint.
-
FAILED: When a job reaches a Fail Checkpoint or times out.
-
CANCELLED: When a job has been cancelled by a command or user action.
-
DELETED: When a job has been deleted by a command or user action.
Each event typically includes:
-
Timestamp of the event.
-
The
job_idand thecheckpoint_id/name/typeit occurred at. -
The
queue_typeandjob_stateat the time of the event. -
A plain-text summary of the event.
-
A snapshot of the
msgobject (Only if Event Data Storage is set to “Full”) -
The current
attemptnumber for the job.
Configurable Event Data Storage
To manage storage consumption, you can configure the level of detail stored for each job event via the EVENT_DATA_STORAGE setting:
-
'Compact': Stores only essential event metadata, suitable for general tracking and auditing.
-
'Full': Includes a complete snapshot of the
msgobject at the time the event occurred. This provides deep debugging capabilities by allowing you to inspect the message content at any point in the job's history, but consumes significantly more storage.
Control Commands
The Checkpoint node can be controlled by sending it a message with a msg.control_cmd property. These commands allow for dynamic management of the queue and individual jobs.
|
Command |
Description |
Applies to Checkpoint Type |
Example msg |
|---|---|---|---|
|
PAUSE_CHECKPOINT |
Pauses the checkpoint, preventing it from processing new jobs from its queue. |
|
|
|
RESUME_CHECKPOINT |
Resumes a paused checkpoint, allowing it to continue processing jobs. |
|
|
|
PUSH_JOB_EVENT |
Adds a custom event to a specific job's history. Requires |
All |
|
|
GET_GROUPED_QUEUE_LIST |
Retrieves a list of queued jobs, grouped by queue type ( |
All |
|
|
GET_FLAT_QUEUE_LIST |
Retrieves a single flat list of all queued jobs. The result is sent to the node's second output. |
All |
|
|
RESET_QUEUE |
Deletes all jobs currently queued at this specific checkpoint. |
All |
|
|
DELETE_JOB |
Permanently deletes a single job from the database, regardless of its state. Requires |
All |
|
|
CANCEL_JOB |
Cancels a job, setting its state to |
All |
|
|
RETRY_JOB |
Manually retries a |
|
|
|
RELEASE_WAITING_JOB |
Releases a single job held at a |
|
|
|
RELEASE_ALL_WAITING_JOBS |
Releases all jobs currently held at a |
|
|
|
CLEAN_DATABASE |
Deletes all jobs from the database. Requires a |
All |
|
Reactivity and Timing of Checkpoints
Checkpoint Nodes leverage an internal, asynchronous scheduler to manage job queues, process events, and maintain job states. This design ensures robustness and resilience, but it also means that job processing is not instantaneous. Understanding the timing characteristics of the two available queue modes is essential for optimizing your flows.
Understanding the Two Queue Modes
The most significant configuration for a Checkpoint is its Queue Mode. This choice fundamentally changes how jobs are ingested, processed, and sent to the next node.
|
Queue Mode Option |
How it Works |
Output Pattern |
Best Use Case |
|---|---|---|---|
|
Batch Burst (Durable) DEFAULT |
Persists all jobs to the database first, then the adaptive scheduler releases the entire queue in a single, powerful operation. |
All jobs in a batch are sent out at roughly the same time. |
Processing entire datasets as a single unit; ensuring no data is lost on crash; critical jobs. |
|
Steady Stream (High-Throughput) NEW |
Buffers jobs in memory and releases them at a constant, configured rate (e.g., 10 per second). Jobs are written to the database as they are sent. |
A smooth, steady flow of individual jobs. |
High-volume APIs; preventing downstream overload; fastest latency for non-batch traffic. |
How Checkpoints Process Jobs
1. Core Queue Processing
-
In Batch Burst Mode: The checkpoint periodically evaluates its internal database queue. The frequency of this check dynamically adapts: it speeds up when there are many jobs waiting (as often as every 3 seconds) and slows down when the queue is empty (up to every 15 seconds), releasing all ready jobs in one go.
-
In Steady Stream Mode: The checkpoint uses a fixed-interval scheduler (typically every 1 second) to process its in-memory buffer. It sends out a number of jobs that adheres to the configured
RATE_LIMIT, creating a predictable, constant flow rather than a burst.
2. High-Volume Ingestion
-
In Batch Burst Mode: To ensure durability, incoming jobs are collected in a temporary batch. When this batch meets a threshold (e.g., 50 messages) or a time limit is reached (e.g., 5 seconds), the entire batch is written to the database queue for persistence before it is considered for processing.
-
In Steady Stream Mode: Incoming jobs are added to a lightweight in-memory buffer with minimal overhead. They are only persisted to the database at the moment they are processed and sent out of the node by the rate-limiter.
3. Common Scheduled and Maintenance Tasks
The following background tasks run independently of the chosen queue mode and apply to specific checkpoint types:
-
Scheduled Jobs (
StartCheckpoints): The scheduler periodically checks for jobs with amsg.qibb.scheduled_attime. Once the schedule arrives, jobs are moved into the appropriate queue (IMMEDIATEfor Batch Burst, or the in-memory buffer for Steady Stream). Expect a delay of 5 seconds to a minute for jobs to be picked up after their scheduled time. -
Automatic Retries (
StartCheckpoints): When a job fails, the Start Checkpoint re-schedules it for a future retry using an exponential backoff strategy (e.g., 10s, 20s, 40s...). The scheduler checks for jobs to retry approximately every 30 seconds. -
Waiting Jobs (
WaitCheckpoints):WaitCheckpoints inherently operate in a burst-like fashion. Jobs are held durably in aWAITINGstate. When approved, they are moved to theIMMEDIATEqueue and are picked up by the scheduler in the next processing burst, typically within 5 to 60 seconds. -
Flagging Stalled Jobs (
StartCheckpoints): The system periodically (approx. every 5 minutes) identifies jobs that have been in aRUNNINGstate for too long (default: 5 minutes) and automatically flags them asSTALLEDfor review.
Latency and Responsiveness
Your choice of queue mode directly impacts the latency profile of your flow:
-
Batch Burst Latency (The "Floodgate"): Jobs experience a predictable delay while they are queued, determined by the adaptive scheduler's interval (3-15 seconds). The key benefit is that all jobs in a large batch will have a similar latency and will be delivered as a cohesive group. The system is highly reactive to load, as the processing interval shortens automatically to clear backlogs faster.
-
Steady Stream Latency (The "Conveyor Belt"): This mode offers the lowest possible latency for the first job in a batch (typically ~1 second). However, for a large batch, the last job will have a higher latency as it waits its turn on the conveyor belt (e.g., in a batch of 50 with a rate limit of 10/s, the last job will have a latency of ~5 seconds). This mode provides excellent responsiveness for single messages and smooths out large bursts to protect downstream systems.
Performance Tip: Consider the Bigger Picture
Remember, the performance of any Checkpoint is influenced by its environment. An undersized app size or a heavy, concurrent workload in other parts of your flow can impact processing speed of jobs and increase latency. Always consider the overall system load when tuning your checkpoints.